Self-attention
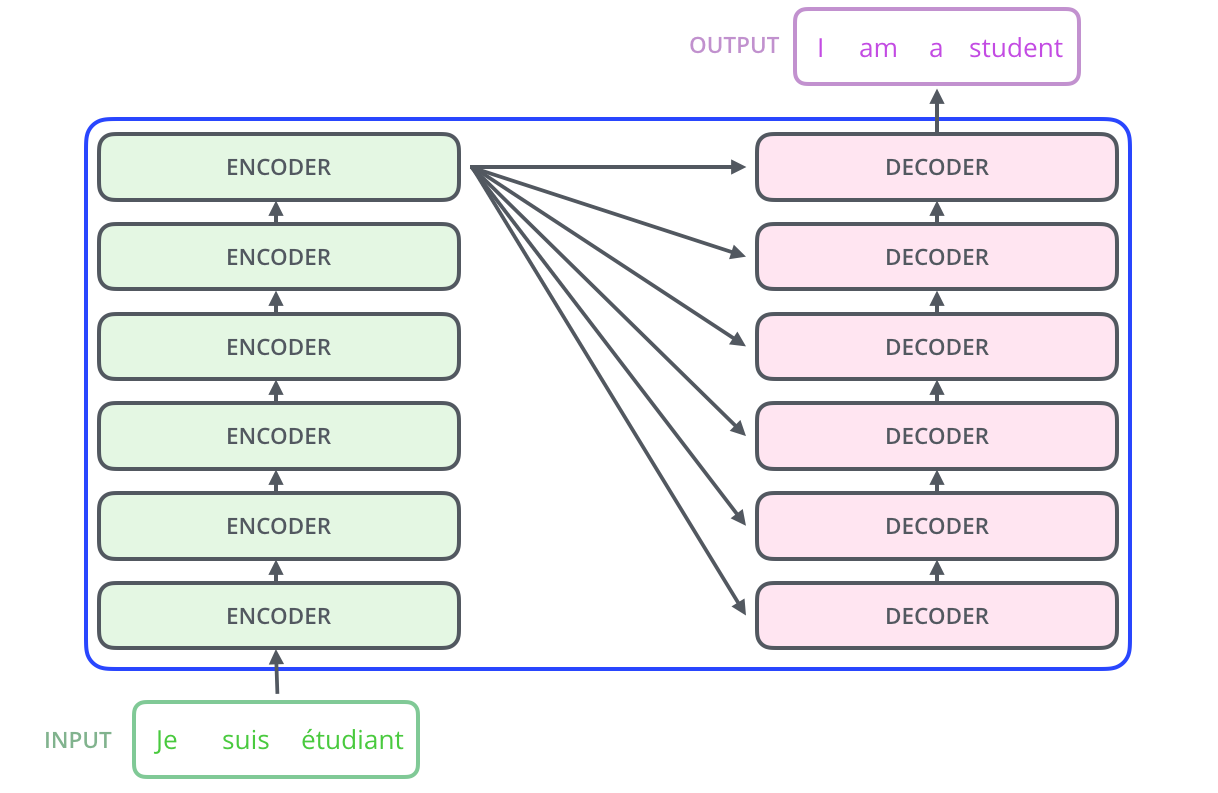
总览图:
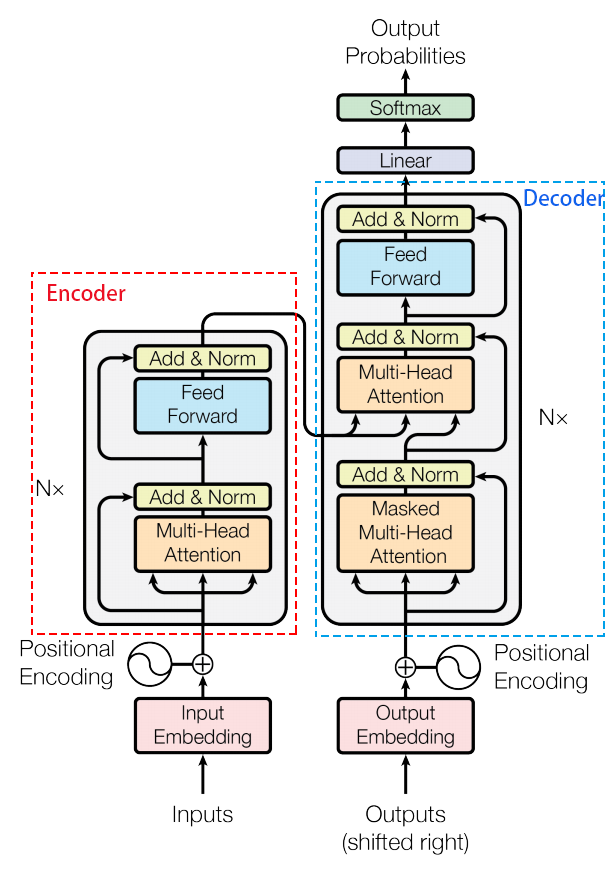
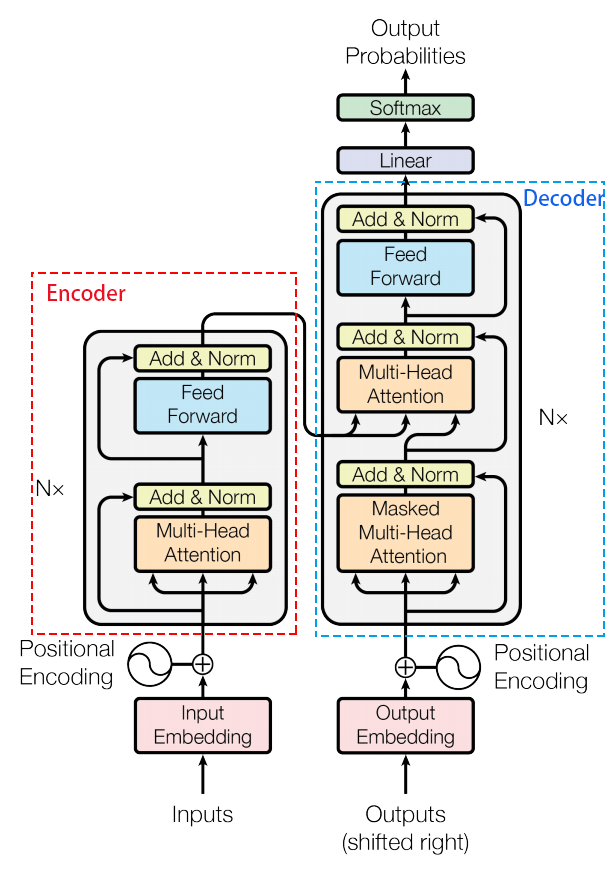
编码器(Encoder)
编码器由 NN 层相同的模块堆叠而成,每层包含两个子层:
多头自注意力机制(Multi-Head Self-Attention):计算输入序列中每个词与其他词的相关性。
前馈神经网络(Feed-Forward Neural Network):对每个词进行独立的非线性变换。
每个子层后面都接有 残差连接(Residual Connection) 和 层归一化(Layer Normalization)。
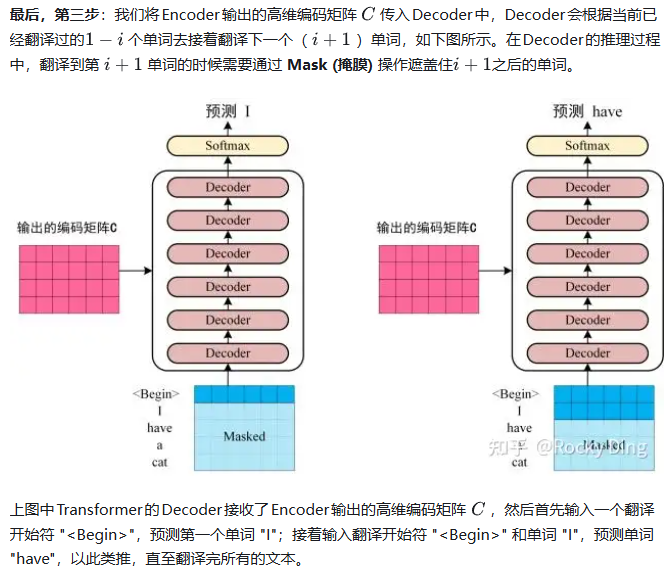
解码器(Decoder)
解码器也由 NN 层相同的模块堆叠而成,每层包含三个子层:
掩码多头自注意力机制(Masked Multi-Head Self-Attention):计算输出序列中每个词与前面词的相关性(使用掩码防止未来信息泄露)。
编码器-解码器注意力机制(Encoder-Decoder Attention):计算输出序列与输入序列的相关性。
前馈神经网络(Feed-Forward Neural Network):对每个词进行独立的非线性变换。
同样,每个子层后面都接有残差连接和层归一化。
最后输出的Linear层:
把输出的embedding转化回人类方便理解的token。
Positional Encoding
transformer模型中缺少一种解释输入序列中单词顺序的方法,它跟序列模型还不不一样。为了处理这个问题,transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下:
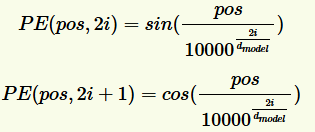
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
最后把这个Positional Encoding与embedding的值相加,作为输入送到下一层。
自注意力公式:

流程描述:
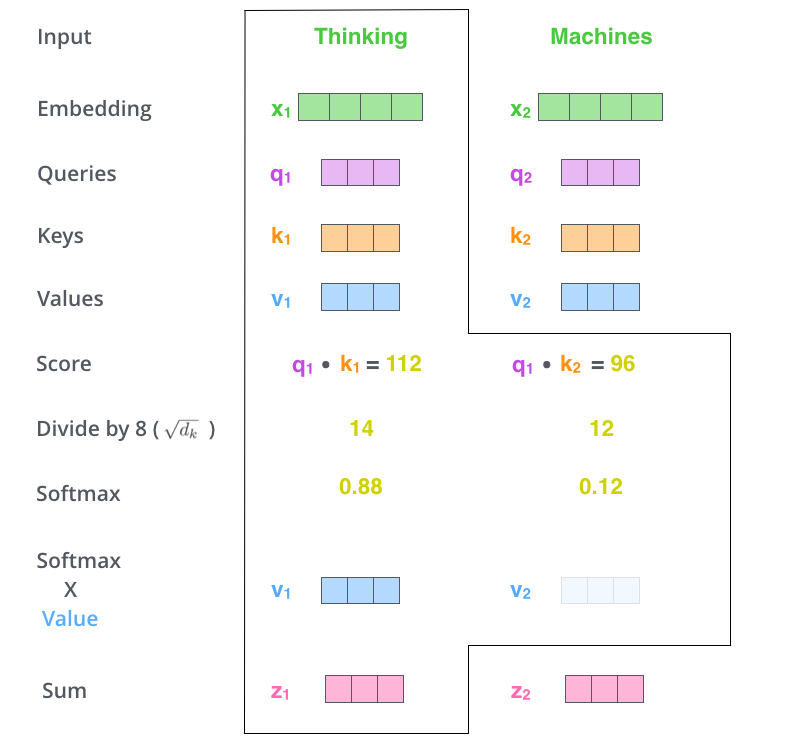
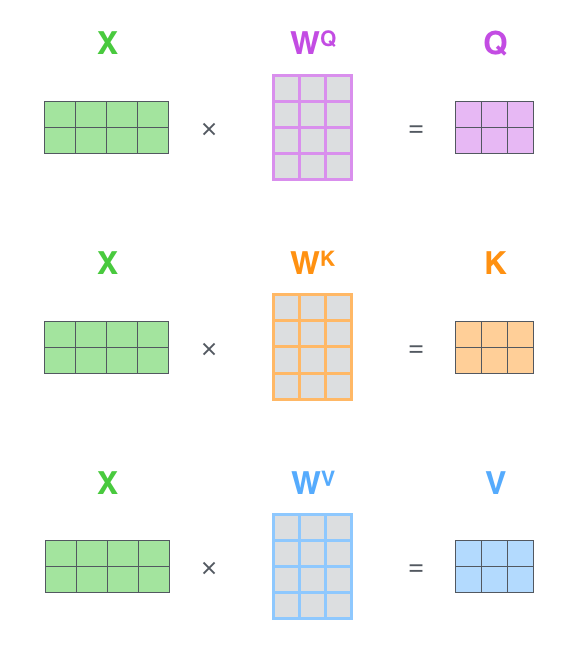
首先,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和embedding的维度一样,其值在BP的过程中会一直进行更新,得到的这三个向量的维度是64。
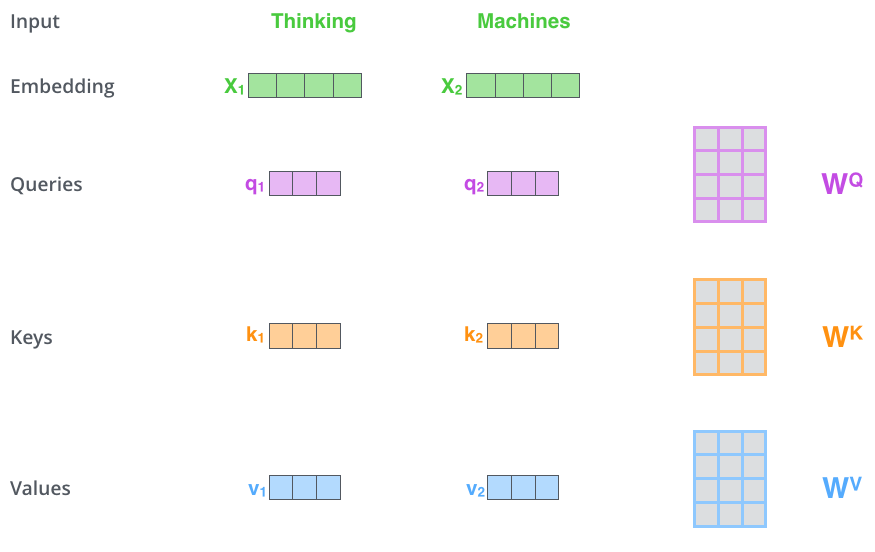
计算self-attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是Query与Key做点成。
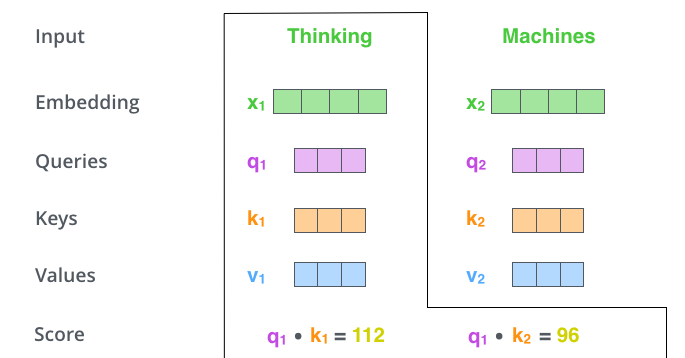
以下图为例,首先我们需要针对Thinking这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即q1·k1,然后是针对于第二个词即q1·k2。
计算a对b的关注度,就是Qa*Kb
接下来,把点成的结果除以一个常数,这里我们除以8,这个值一般是采用上文提到的矩阵的第一个维度的开方即64的开方8,当然也可以选择其他的值,然后把得到的结果做一个softmax的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会会很大。
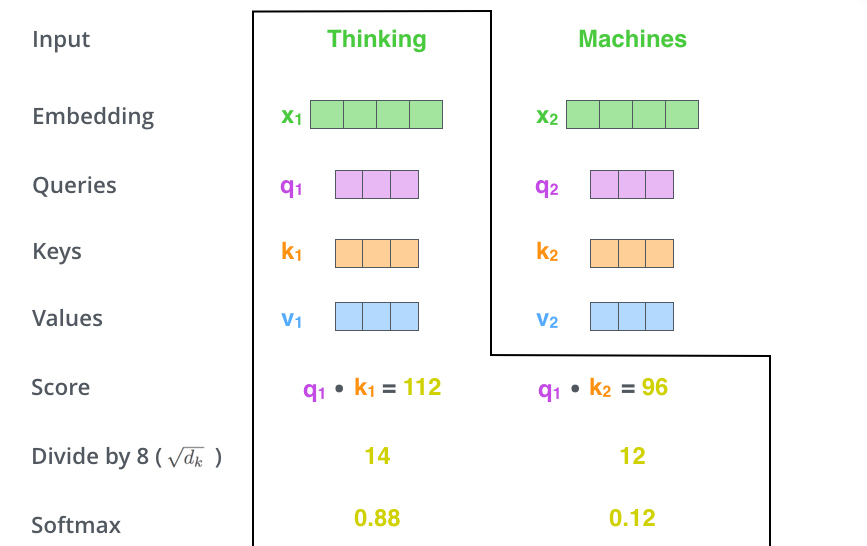
下一步就是把Value和softmax得到的值进行相乘,并相加,得到的结果即是self-attetion在当前节点的值。
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出Query, Key, Value的矩阵,然后把embedding的值与三个矩阵直接相乘,把得到的新矩阵 Q 与 K 相乘,乘以一个常数,做softmax操作,最后乘上 V 矩阵。
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。
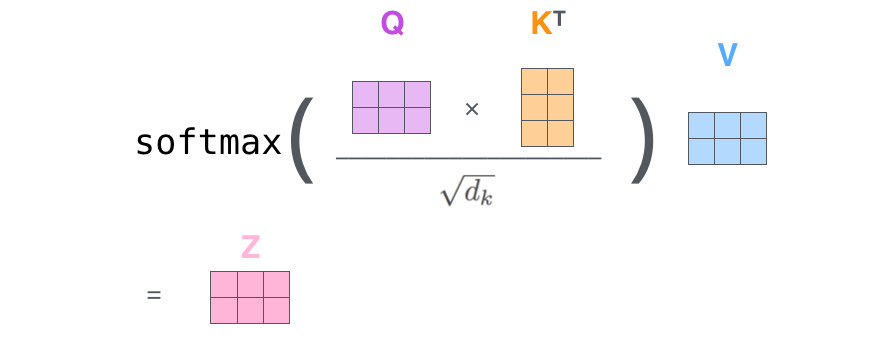
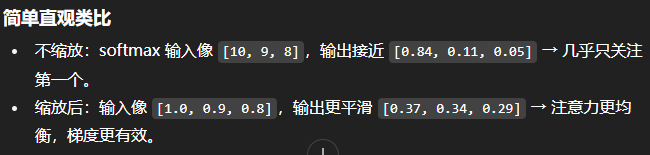
为什么要除以根号dk(矩阵的第一个维度)?
简而言之,缩放是为了:避免softmax导致的梯度极端化、避免梯度消失
softmax:
将一组任意实数“转换成概率分布”的数学函数,让每个类别的可能性在 0~1 之间,且总和为 1。
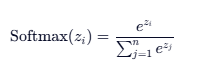



多头注意力:
就是说不仅仅只初始化一组Q、K、V的矩阵,而是初始化多组,tranformer是使用了8组,所以最后得到的结果是8个矩阵。
为什么选用LN而不是BN?
(1) 序列任务中 batch 大小不稳定,LN不会受到batch size的影响
在 NLP(自然语言处理)里,句子长短不同,padding 方式不同,如果用 BN,就需要在 batch 内统计均值/方差,容易受到 padding 或 batch size 的影响。
LN 只看 单个序列自身的特征维度,不会受到 batch 的影响,更稳定。
(2) 推理阶段的灵活性
BN 在训练和推理时不同:训练时用 batch 统计,推理时要用 移动平均 的均值和方差。
对 Transformer 这种经常需要小 batch(甚至 batch=1)推理的模型,BN 会变得不稳定。
LN 在训练和推理阶段完全一致,不依赖 batch,部署方便。
(3) 自注意力机制的特点
在 Self-Attention 里,每个 token 都会跟序列里其他 token 交互。
LN 保证了每个 token 的 embedding 在同一个层面上有统一的分布,能稳定训练。
BN 更适合计算机视觉(CV)这种“二维网格的图像特征”,但在 NLP 这种一维序列上效果不好。
(4) BN在小 batch效果不好,而LN不依赖batch size
Transformer(尤其是 NLP 预训练)常常用 小 batch(甚至单句推理),BN 在小 batch 时统计的均值/方差会非常不准确。
LN 完全不依赖 batch size,天然适合。
总结一句话
👉 Transformer 用 LayerNorm,而不是 BatchNorm,因为它:
不依赖 batch 统计,更稳定;
适合小 batch / 单样本推理;
在序列建模(如 NLP)中效果更好;
训练和推理阶段表现一致,工程上更方便。
masked mutil-head attetion
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
padding mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。