各种发展与微调的导视
小白也能读懂的AIGC扩散(Diffusion)模型系列讲解
理解扩散模型的损失函数



SD中的U-Net的结构(核心知识)
深入浅出完整解析Stable Diffusion(SD)核心基础知识
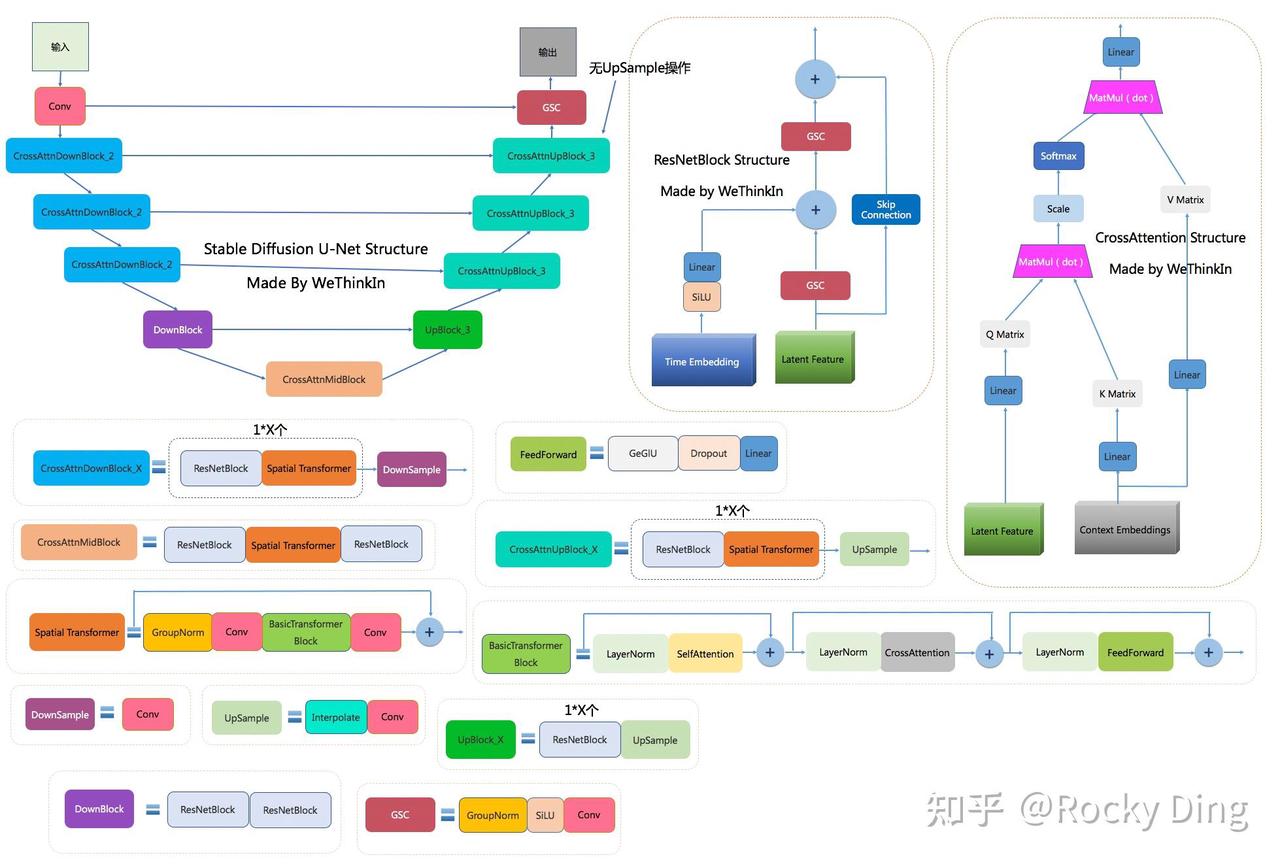
上图中包含Stable Diffusion U-Net的十四个基本模块:
GSC模块:Stable Diffusion U-Net中的最小组件之一,由GroupNorm+SiLU+Conv三者组成。
DownSample模块:Stable Diffusion U-Net中的下采样组件,使用了Conv(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))进行采下采样。
UpSample模块:Stable Diffusion U-Net中的上采样组件,由插值算法(nearest)+Conv组成。
ResNetBlock模块:借鉴ResNet模型的“残差结构”,让网络能够构建的更深的同时,将Time Embedding信息嵌入模型。
CrossAttention模块:将文本的语义信息与图像的语义信息进行Attention机制,增强输入文本Prompt对生成图片的控制。
SelfAttention模块:SelfAttention模块的整体结构与CrossAttention模块相同,这是输入全部都是图像信息,不再输入文本信息。
FeedForward模块:Attention机制中的经典模块,由GeGlU+Dropout+Linear组成。
BasicTransformer Block模块:由LayerNorm+SelfAttention+CrossAttention+FeedForward组成,是多重Attention机制的级联,并且也借鉴ResNet模型的“残差结构”。通过加深网络和多Attention机制,大幅增强模型的学习能力与图文的匹配能力。
Spatial Transformer模块:由GroupNorm+Conv+BasicTransformer Block+Conv构成,ResNet模型的“残差结构”依旧没有缺席。
DownBlock模块:由两个ResNetBlock模块组成。
UpBlock_X模块:由X个ResNetBlock模块和一个UpSample模块组成。
CrossAttnDownBlock_X模块:是Stable Diffusion U-Net中Encoder部分的主要模块,由X个(ResNetBlock模块+Spatial Transformer模块)+DownSample模块组成。
CrossAttnUpBlock_X模块:是Stable Diffusion U-Net中Decoder部分的主要模块,由X个(ResNetBlock模块+Spatial Transformer模块)+UpSample模块组成。
CrossAttnMidBlock模块:是Stable Diffusion U-Net中Encoder和ecoder连接的部分,由ResNetBlock+Spatial Transformer+ResNetBlock组成。
(1)时间步t是怎么嵌入到扩散模型的?
Time Embedding正是输入到ResNetBlock模块中,为U-Net引入了时间信息(时间步长T,T的大小代表了噪声扰动的强度),模拟一个随时间变化不断增加不同强度噪声扰动的过程,让SD模型能够更好地理解时间相关性。
由于在每个ResNetBlock模块中都有Time Embedding,就能告诉U-Net现在是整个迭代过程的哪一步,并及时控制U-Net够根据不同的输入特征和迭代阶段而预测不同的噪声残差。
在 Diffusion 模型(如 DDPM、DDIM、Stable Diffusion、DiT 等)中,时间步 tt 表示扩散过程的第几步(noise level),它控制着模型当前需要处理的噪声强度。模型必须知道 tt 才能“去噪”正确。
嵌入时间步 tt 的主要流程是:
把离散时间步 t 通过 正弦/余弦位置编码,转为连续向量(time embedding)
time embedding经过一个小的 MLP(例如两层 Linear + 激活函数)映射为与特征通道数一致的向量
加到 U-Net/Transformer 的每一层(通常是残差块)中
时间步嵌入的原理
最常用的做法是 正弦/余弦位置编码(sinusoidal positional encoding),类似 Transformer 的位置编码。 公式:

这样可以把一个标量 tt 编成 dd-维向量(通常 d=128d = 128 或 256256)。
然后通过一个 MLP(两层全连接+激活)映射到模型内部通道维度(如 320、768)。
代码示例(PyTorch, 来自 DDPM/Stable Diffusion)
import torch
import torch.nn as nn
import math
class SinusoidalTimeEmbedding(nn.Module):
def __init__(self, embedding_dim):
super().__init__()
self.embedding_dim = embedding_dim
def forward(self, t):
"""
t: [batch_size] 时间步标量
return: [batch_size, embedding_dim] 正弦余弦编码
"""
half_dim = self.embedding_dim // 2
# 生成频率 [0, 1, 2, ...]
freqs = torch.exp(
-math.log(10000) * torch.arange(0, half_dim, dtype=torch.float32) / half_dim
).to(t.device)
# [batch_size, half_dim]
angles = t[:, None].float() * freqs[None]
emb = torch.cat([torch.sin(angles), torch.cos(angles)], dim=-1)
return emb # shape: [B, embedding_dim]
class TimeEmbeddingMLP(nn.Module):
def __init__(self, time_dim, model_channels):
super().__init__()
self.time_mlp = nn.Sequential(
nn.Linear(time_dim, model_channels * 4),
nn.SiLU(), # 或 nn.Swish()
nn.Linear(model_channels * 4, model_channels)
)
def forward(self, t):
"""
输入: t [B] 时间步
输出: [B, model_channels]
"""
return self.time_mlp(t)
# 例子:把时间步嵌入到 U-Net
t = torch.randint(0, 1000, (8,)) # batch_size=8
time_embed = SinusoidalTimeEmbedding(128)(t) # [8, 128]
time_cond = TimeEmbeddingMLP(128, model_channels=320)(time_embed) # [8, 320]嵌入后如何用?
时间步嵌入 不会单独输入网络,而是加到每个残差块(ResBlock)的中间层:
# 伪代码
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, time_emb_dim):
super().__init__()
self.time_proj = nn.Linear(time_emb_dim, out_channels)
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1)
def forward(self, x, t_emb):
# t_emb: [B, time_emb_dim]
h = self.conv1(x)
# 加入时间步
h = h + self.time_proj(t_emb)[:, :, None, None]
h = torch.relu(h)
h = self.conv2(h)
return h这样,每一层卷积都知道当前是哪个扩散步骤 tt。
其他方式(Transformer-based DiT)
在 DiT (Diffusion Transformer) 里,时间步 tt 会被嵌入成一个向量,然后:
加到 patch embedding 上(类似位置编码)
或者作为 Adaptive LayerNorm / FiLM 的调制因子
(2)多模态实现的关键:条件控制&Cross-Attention
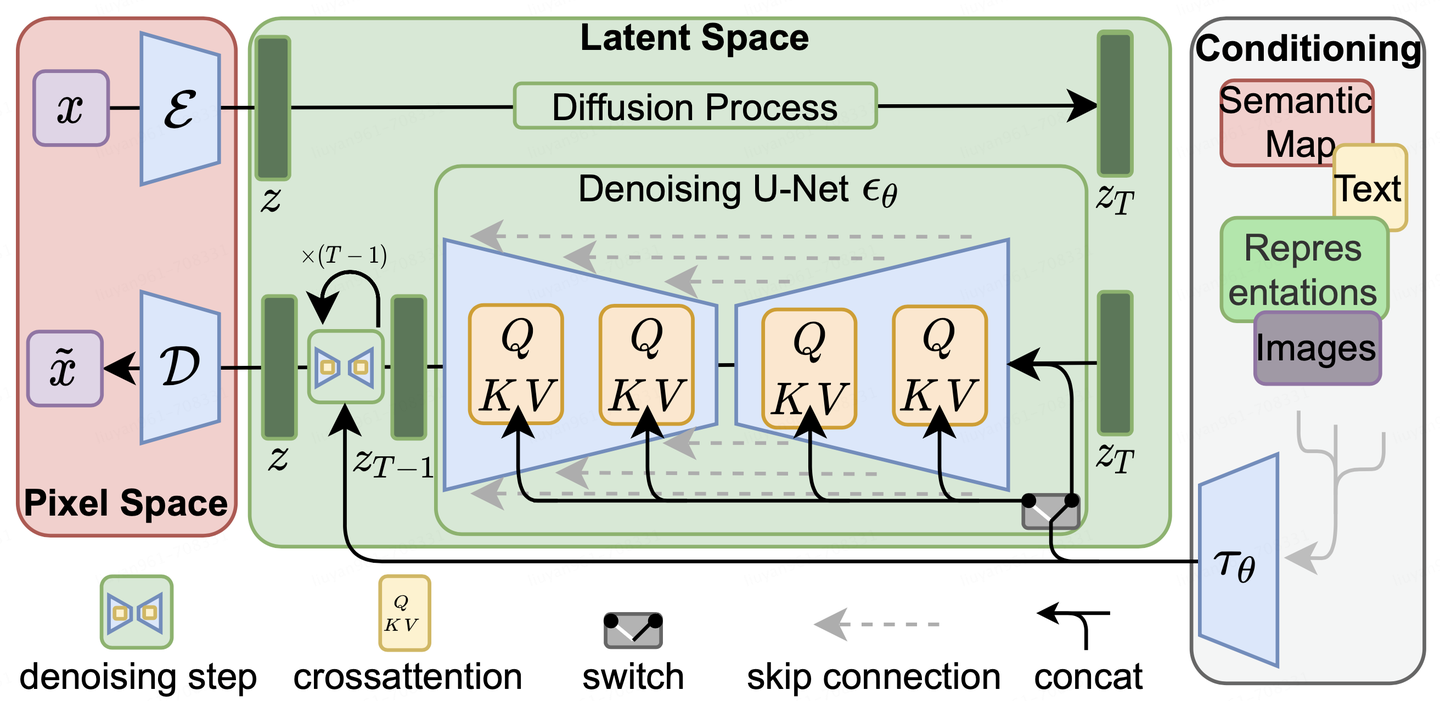
LDM(Latent Diffusion Model)实现多模态主要通过条件控制机制,核心思想就是把所有模态的信息 编码成统一向量空间,再输入扩散网络做反向去噪。
图片通过视觉编码器(Vision Encoder)转成特征向量。
文本通过语言编码器(Text Encoder)转成特征向量。
这些特征向量会被注入到 U-Net(核心去噪网络)的不同层,实现条件控制。
它并不是直接在像素空间中处理图像,而是在潜空间(latent space)中进行扩散与生成,并通过条件编码器将不同模态信息(文本、图像、语音等)映射到同一个潜空间中来实现跨模态控制。 U-Net + Cross-Attention
LDM 多模态主要依赖 Cross-Attention 层:
Q:来自潜空间特征(待生成图像的表示)
K/V:来自条件模态(如文本编码器的输出)
在Stable Diffusion中主要使用了Text Encoder部分。CLIP Text Encoder模型将输入的文本Prompt进行编码,转换成Text Embeddings(文本的语义信息),通过前面章节提到的U-Net网络的CrossAttention模块嵌入Stable Diffusion中作为Condition条件,对生成图像的内容进行一定程度上的控制与引导,目前SD模型使用的的是CLIP ViT-L/14中的Text Encoder模型。
(3)scheduler
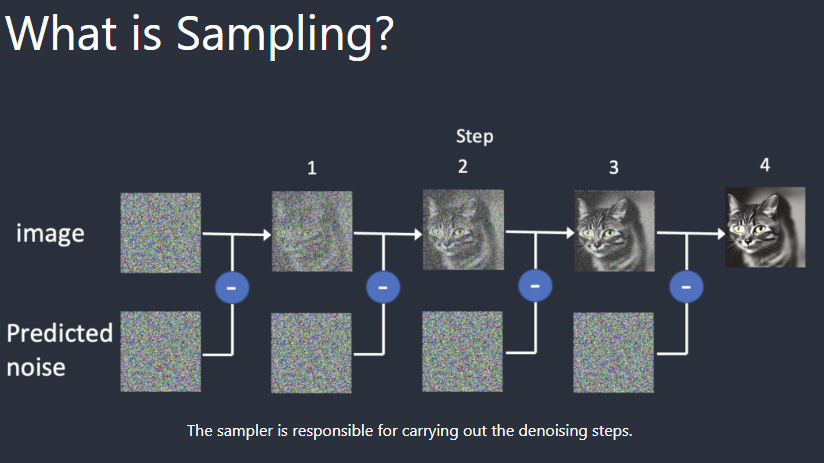
在了解schedulers之前,首先,我们要区分Diffusion里的scheduler和pytorch里的scheduler,前者是一个采样器(samplers),用于把噪声图像还原为原始图像;后者是一个学习率策略(例如余弦退火策略,指数衰减策略等)
Diffusion的scheduler,它的功能是实现逆向扩散,直观上理解的话它就是一个采样器,循环多个step把噪声图像逐渐还原为原始图像。根据采样方式不同,scheduler也有许多版本,包括DDPM,DDIM,DPM++ 2M Karras等。
注意:我们把去噪的过程定义为采样。使用采样的方法,称之为采样器。
ddpm
DDPM一个最大的缺点是需要设置较长的扩散步数才能得到好的效果,这导致了生成样本的速度较慢
ddim
不再限制前向(扩散)过程必须是一个Markov链,这使得DDIM可以采用更小的采样步数来加速生成过程
哪个Schedulers最好?
目前还没有公认的最好的schedulers
如果想生成的更快,图像收敛(即种子一样,每次生成的固定),质量相对还可以的话,推荐:
DPM++ 2M Karras with 20-30 steps
UniPC with 20-30 steps
如果想要更好的图片质量,不考虑是否收敛,推荐:
DPM++ SDE Karras with 10-15 steps。(更慢,但是质量更好)
DDIM with 10-15 steps。
区分Noise scheduler

(4)推理步数(steps、num_inference_steps或者Sampling steps)
num_inference_steps表示SD系列模型在推理过程中的去噪次数或者采样步数。一般来说,我们可以设置num_inference_steps在20-50之间,其中设置的采样步数越大,图像的生成效果越好,但同时生成所需的时间就越长。
到这里大家可能会有疑问,为什么SD系列模型在训练时设置1000的noise scheduler,在推理时却只用设置20-50的noise scheduler?
这是因为,虽然SD模型在训练时参照DDPM采样方法,但推理时可以使用DDIM这个采样方法,DDIM通过去马尔可夫化,让SD模型在推理时可以进行“跳步”,抽取短的子序列作为noise scheduler,大大减少了推理步数。
当然的,除了使用DDIM采样方法,我们也可以使用其他的采样方法,目前主流的采样方法有DPM系列、DPM++系列、Euler系列、LMS系列、Heun、UniPC、Restart等。
(5)CFG (Classifier-Free Guidance)
Classifier-Free Guidance(CFG)是一种在生成模型(尤其是扩散模型,如Stable Diffusion)中常用的技巧,用于在生成过程中控制条件信息的影响力,从而生成更符合指定条件(比如文本提示)的样本。

guidance_scale权重:当设置的guidance_scale越大时,文本的控制力会越强,SD模型生成的图像会和输入文本更一致。
通常guidance_scale可以设置在7-8.5之间,就会有不错的生成效果。
如果使用非常大的guidance_scale值(比如11-12),生成的图像可能会过饱和,同时多样性会降低。
CFG的核心是 在训练阶段,让模型即学会有条件生成,又学会无条件生成(在训练时以一定概率drop掉text embedding)。然后在采样阶段通过两者组合来强化条件效果。
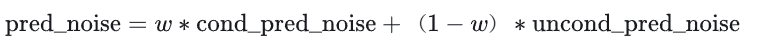
其中w代表guidance_scale,当w越大时,输入文本起的作用越大,即生成的图像更和输入文本一致,当被设置为时,图像的生成是无条件的,输入文本会被忽略。
(6)Negative Prompt
我们可以使用Negative Prompt来避免生成我们不想要的内容,从而改善图像生成效果。
(7)interppolate 上采样块
1. 在图像处理中的 interpolate
最常见的应用是图像缩放/重采样:
上采样 (Upsampling):把图像尺寸变大(如 64×64 → 256×256)。
下采样 (Downsampling):把图像尺寸变小(如 256×256 → 64×64)。
在 PyTorch 中,你可能见过:
import torch.nn.functional as F x_resized = F.interpolate(x, size=(256, 256), mode='bilinear')
这里 mode 决定插值算法:
nearest:最近邻插值(最简单,像素块放大)bilinear:双线性插值(常用于图像)bicubic:双三次插值(效果更平滑)trilinear:三线性插值(3D 数据)
2. 在序列数据中的 interpolate
处理时间序列缺失值:用插值方法填补缺失点。
模型预测时,为了平滑曲线,也会用插值。
例如:
import torch x = torch.tensor([1., 2., 4.]) x_interp = torch.interpolate(x, ...) # 插值后得到 1, 2, 3, 4
图像可以看作高维随机变量

CLIP 模型
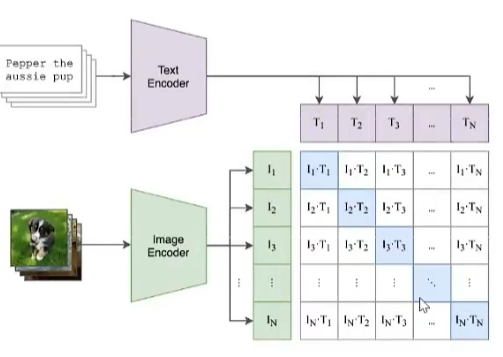
CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型。其中Text Encoder用来提取文本的特征,可以使用NLP中常用的text transformer模型作为Text Encoder;而Image Encoder主要用来提取图像的特征,可以使用CNN/Vision transformer模型(ResNet和ViT等)作为Image Encoder。与此同时,他直接使用4亿个图片与标签文本对数据集进行训练,来学习图片与本文内容的对应关系。
与U-Net的Encoder和Decoder一样,CLIP的Text Encoder和Image Encoder也能非常灵活的切换,庞大图片与标签文本数据的预训练赋予了CLIP强大的zero-shot分类能力。
CLIP在训练时,从训练集中随机取出一张图片和标签文本,接着CLIP模型的任务主要是通过Text Encoder和Image Encoder分别将标签文本和图片提取embedding向量,然后用余弦相似度(cosine similarity)来比较两个embedding向量的相似性,以判断随机抽取的标签文本和图片是否匹配,并进行梯度反向传播,不断进行优化训练
完成CLIP的训练后,输入配对的图片和标签文本,则Text Encoder和Image Encoder可以输出相似的embedding向量,计算余弦相似度就可以得到接近1的结果。同时对于不匹配的图片和标签文本,输出的embedding向量计算余弦相似度则会接近0。
就这样,CLIP成为了计算机视觉和自然语言处理这两大AI方向的“桥梁”,从此AI领域的多模态应用有了经典的基石模型。
LDM
为了避免AE压缩出的latent space过于发散(high variance),通常会把latent space的特征分布用KL散度对齐到标准正态空间。
相近的说法:
为了避免隐空间较大的方差,引入了KL正则化或者VQ正则化项。
获得了通用压缩模型,其潜在空间可用于训练多个生成模型,也可用于其他下游应用,例如单图像CLIP引导合成。