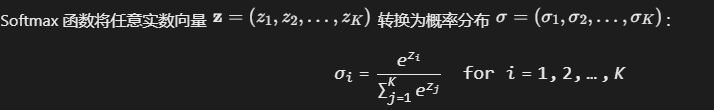
概率分布函数与 Softmax 方法详解
一、概率分布函数 (Probability Distribution Function)
定义
概率分布函数是描述随机变量取值概率规律的数学函数。它定义了随机变量取特定值或落入特定区间的可能性。
核心类型
graph TD
A[概率分布] --> B[离散型]
A --> C[连续型]
B --> D[概率质量函数 PMF]
C --> E[概率密度函数 PDF]
D --> F[描述离散变量取特定值的概率]
E --> G[描述连续变量在区间内的概率]关键特性
非负性:
P(x) \geq 0对所有x归一性:
\sum P(x) = 1(离散)或\int_{-\infty}^{\infty} f(x)dx = 1(连续)归一性:归一性(Normalization)是概率论和统计学中的一个核心概念,指的是一个概率分布的所有可能结果的概率之和等于1。
可测性:可以计算任意事件发生的概率
常见概率分布
数学表示
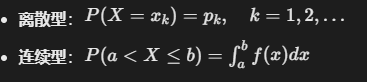
二、Softmax 方法:实数向量到概率分布的转换
问题背景
在机器学习和深度学习中,模型的原始输出(logits)通常是任意实数:
可能为负数
取值范围不受限制
各元素之间没有概率关系
而我们需要:
概率值在 [0,1] 区间
所有概率和为 1
表示分类的概率分布
Softmax 定义
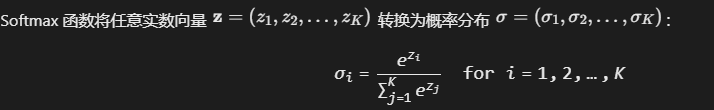
转换过程
graph LR
A[原始实数向量] --> B[指数运算]
B --> C[指数和]
C --> D[归一化]
D --> E[概率分布]关键特性
输出范围:
0 < \sigma_i < 1归一性:
\sum_{i=1}^K \sigma_i = 1单调性:保持原始值的大小关系
放大差异:指数运算放大较大值的优势
示例演示
.png)
为什么需要 Softmax?
概率解释:将模型输出转化为可解释的概率
多分类决策:支持选择概率最大的类别
损失计算:与交叉熵损失完美配合
梯度优化:提供良好的优化特性
三、Softmax 的数学性质
与最大函数的关系
Softmax 是 max 函数的"软化"版本:
\text{softmax}(\mathbf{z})_i \approx \begin{cases}
1 & \text{if } z_i = \max(\mathbf{z}) \\
0 & \text{otherwise}
\end{cases}当 \max(\mathbf{z}) \gg 其他值时
温度参数
引入温度参数控制"软化"程度:
\sigma_i = \frac{e^{z_i / T}}{\sum_{j=1}^K e^{z_j / T}}T > 1:更均匀的分布T < 1:更尖锐的分布T \to 0:接近 one-hot 编码
数值稳定性
实际实现使用:
\sigma_i = \frac{e^{z_i - \max(\mathbf{z})}}{\sum_{j=1}^K e^{z_j - \max(\mathbf{z})}}避免指数运算溢出
四、Softmax 在深度学习中的应用
多分类输出层
class Classifier(nn.Module):
def __init__(self, input_size, num_classes):
super().__init__()
self.linear = nn.Linear(input_size, num_classes)
def forward(self, x):
logits = self.linear(x)
return torch.softmax(logits, dim=1) # 转换为概率分布注意力机制
def attention(query, key, value):
# 计算注意力分数
scores = torch.matmul(query, key.transpose(-2, -1))
# 转换为注意力权重(概率分布)
attn_weights = torch.softmax(scores, dim=-1)
return torch.matmul(attn_weights, value)概率采样
# 从概率分布中采样
probs = torch.softmax(logits, dim=-1)
sampled_index = torch.multinomial(probs, 1)五、与其他方法的比较
六、Softmax 的局限性及解决方案
局限性
类别互斥假设:不适合多标签问题
指数计算成本:类别多时计算量大
零概率问题:不能表示绝对不可能的事件
解决方案
多标签问题:使用 sigmoid + 二元交叉熵
# 多标签分类
outputs = torch.sigmoid(logits)
loss = nn.BCELoss()(outputs, targets)大规模分类:使用分层 Softmax 或采样方法
# 近似Softmax (负采样)
loss = nn.SampledSoftmaxLoss()(logits, targets)零概率需求:使用混合分布或先验知识
# 添加先验概率
adjusted_logits = logits + prior_log_probs
probs = torch.softmax(adjusted_logits, dim=-1)七、可视化理解
graph LR
A[模型原始输出] -->|任意实数| B(Softmax函数)
B --> C[概率分布]
C --> D[满足概率公理]
D --> E[可用于决策]
style A fill:#f9f,stroke:#333
style B fill:#9f9,stroke:#333
style C fill:#ff9,stroke:#333概率分布函数是描述随机现象的基础数学工具,而 Softmax 方法是将深度学习模型原始输出转换为有效概率分布的关键技术。通过指数运算和归一化,Softmax 将任意实数向量转换为符合概率公理(非负性、归一性)的分布,使模型输出具有概率解释性,为分类决策、不确定性估计和概率建模提供了数学基础。理解这一转换过程对于掌握现代深度学习模型的工作原理至关重要。

.PNG)