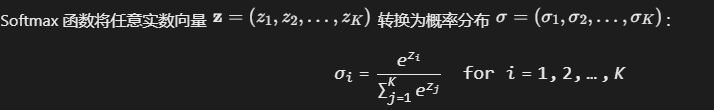.PNG)
transformer如何成为今天AI的地基?
transformer是怎么工作的:
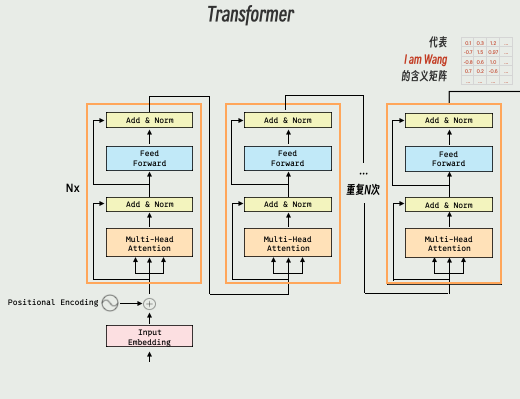
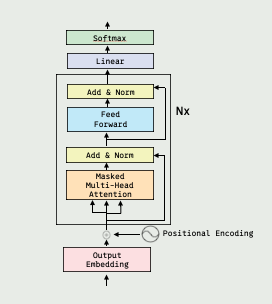
编码器:
左边乘以N的标记。这代表我们输入的“I am Wang”经过方块中的运算,产生的结果并不直接就是含义矩阵,而是又进行了一次相同结构的运算。这样的运算一共进行了N次,最后才得出最终的含义矩阵。
解码器:
把人类无法理解的含义矩阵转换回了可以理解的语言
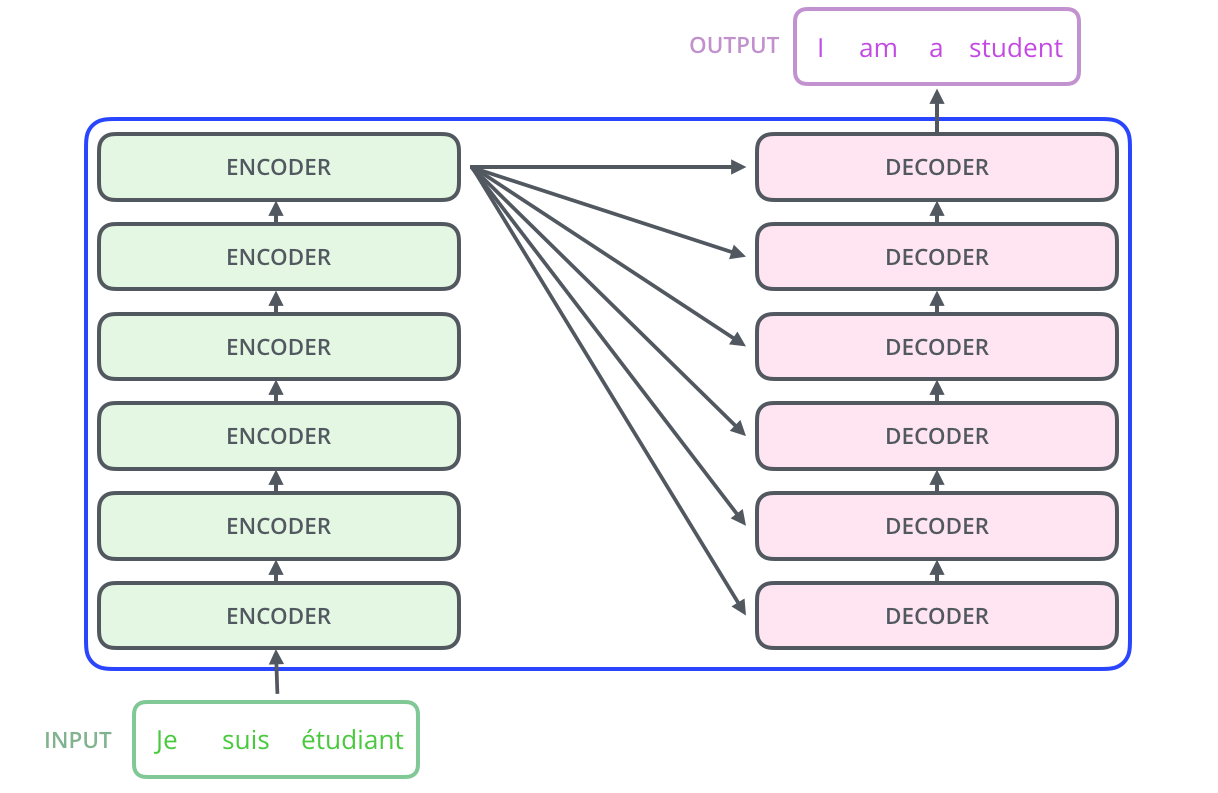
解码器和编码器的工作过程不太一样。编码时,我们把“I am Wang”这句话整个传到编码器里,然后模型一下就生成了整句话的含义矩阵。但是解码时,解码器却是一个词一个词地生成翻译的。
解码器有两个输入:
来自编码器的含义矩阵。
解码器当前已经翻译好的文本。
最开始翻译时,我们没有已经翻译好的文本,所以我们传入一个代表“句子开始”的标记。于是,这个“开始标记”配合含义矩阵,经过整个解码器的运算,最后生成的内容是翻译后的第一个词的概率分布。
比如,“I am Wang”的含义矩阵 + “开始标记”之后,解码器的输出就可能是 “我” 10%, “你” 4%, “他” 5%, “苹果” 0.5% 等等。模型认识的每一个词(更准确地说是Token),都会有这样一个概率。GPT-2一共认识50257个token,所以这里就有50257个概率,这5万多个概率加起来正好是100%。
这时,我们一般会选择概率最高的token“我”当作输出,这——就是翻译出来的第一个token了。
注意,在这个过程中,解码器也有一个乘以N的标记,说明这段运算结构也是重复了多次的,和编码器相同。这里每次重复时,含义矩阵的输入是一直不变的。
于是现在我们有了“开始标记”和“我”这两个token。这时我们再把这两个token同时传入解码-器,解码器就会生成下一个token的概率,比如 “是” 80%, “苹果” 0.01% 等等。于是我们就选择出了第二个token “是”。同理再把 “开始标记”、“我”、“是” 传入解码器就会生成 “王”。最后,“开始标记”“我是王” 再传入解码器,解码器就会生成“结束标记”,这样程序就知道翻译已经完成了。
最终“我是王”就是”I am Wang”的最终翻译了。
不难看出,输出时每生成一个token就会完整地跑一遍decoder,所以生成“我是王”这三个token的工作量,要远比生成“I am Wang”含义矩阵的encoder的工作量多得多。而且翻译后的句子越长,二者的工作量差距也就越明显。这也是为什么,大模型API在收费时输出往往比输入贵得多。
Transformer的变种
经过之前的分析,我们不难看出Transformer模型的设计思路:
左边的encoder负责理解文字,右边的decoder负责生成文字。
Decoder-Only架构(GPT系列)
说到生成文字,是不是感觉和现在的大语言模型有点像?
没错,OpenAI很快就发现,右边的解码器其实是可以独立工作的。但如果没有左半边的编码器,那从编码器传过来的“含义矩阵”这个输入,要怎么处理呢?OpenAI直接把和它相关的部分删掉了。
于是,这个模型就只剩下decoder部分了,所以它被叫做decoder-only transformer。而这——就是GPT-2的模型结构。
其实不仅是GPT模型,像Claude、Gemini、DeepSeek、Kimi等等,现在绝大多数大语言模型都是这种decoder-only结构的变种。
这种结构的模型训练起来也是非常方便的。我们可以用任何现成的文本进行训练,比如 “我是老王”。
输入“我”,训练模型输出“是”;
然后输入“我是”,训练模型输出“老”;
输入“我是老”,训练模型输出“王”。
不像训练翻译模型那样的监督学习,人们需要同时提供成对的输入和输出,这里我们只需要提供任意一个有意义的字符串,输入和输出就可以根据规则自动生成。这种训练方式叫做自监督学习。
LLM 训练
1. 规模巨大(“大”在哪?)
表格
💡 “大”不是为了炫技,而是规模带来质变(涌现能力):小模型不会推理,大到一定程度突然会了!
2. 基于 Transformer 架构
LLM 的“大脑”是 Transformer(2017 年 Google 提出)。
它的核心是 自注意力机制(Self-Attention):
能同时关注句子中所有词之间的关系;
比如:“他把书给了她,因为她需要。” → 模型知道“她”指谁。
✅ Transformer 让 LLM 能处理长文本、捕捉复杂依赖,是 LLM 成功的技术基石。
3. 训练大模型
预训练→微调→RLHF
先用海量无标注文本预训练(无监督学习),再用少量标注数据微调SFT
(1)预训练(Pre-training) ——让模型 “见多识广”
核心目标:学习通用语言规律、常识、基础语义关联(如 “猫” 是动物,“红色” 是颜色)。
数据格式:无标注的 “纯文本” 或 “图文对”(无需人工打标签,降低成本)。
数据来源:
文本:开源语料库(如 WikiText、BookCorpus)、新闻文章、小说、论文摘要。
图文:Flickr30k(3 万张图 + 15 万条描述)、COCO(12 万张图 + 50 万条描述)的子集。
构造示例(500 条图文对):
[{"image_path": "pretrain_imgs/001.jpg", "caption": "一只黑色的猫坐在沙发上"},
{"image_path": "pretrain_imgs/002.jpg", "caption": "红色的苹果放在白色盘子里"},
// ... 共500条,图片从Flickr30k截取,描述直接复用数据集自带的caption]关键要求:数据多样性(覆盖不同场景、物体、语言风格),无需精准标注,数量优先。
(2)微调(Fine-tuning) —— 让模型 “听懂指令”
核心目标:学习 “指令→正确回答” 的映射(如 “指令:图中有几只猫?→ 回答:2 只”)。
数据格式:“指令 + 输入(文本 / 图片路径)+ 正确回答” 的三元组(有监督标注)。
数据来源:
手动标注:基于预训练数据集的图片 / 文本,人工写简单指令和回答(500 条仅需 1-2 天)。
工具生成:用 ChatGPT 批量生成(如输入 “给图片描述‘猫坐在沙发上’写 5 条指令”)。
构造示例(500 条):
[{"instruction": "图中的猫是什么颜色?",
"input": "pretrain_imgs/001.jpg", // 图片输入(文本任务可直接填文本)
"response": "黑色"},
{"instruction": "描述图片中的物体和位置关系",
"input": "pretrain_imgs/002.jpg",
"response": "红色的苹果放在白色的盘子里"},
// ... 共500条,指令覆盖“计数、颜色、位置、描述”等简单任务]关键要求:指令清晰、回答准确简洁,场景与目标任务一致(如做医疗模型,指令需是 “解读 X 光片”)。
(3) RLHF(人类反馈强化学习)—— 让模型 “知道好坏”
核心目标:让模型区分 “好回答” 和 “坏回答”,学习人类偏好。
数据格式:“指令 + 输入 + 多个回答 + 人工打分” 的四元组(打分 1-3 分,3 分最好)。
数据来源:从微调数据中选 100 条,用微调后的模型生成 2-3 个不同回答(调整
temperature参数控制多样性),再人工打分。构造示例(100 条):
[{"instruction": "图中有几只猫?",
"input": "pretrain_imgs/001.jpg",
"responses": [{"text": "2只黑色的猫", "score": 3}, // 准确且完整
{"text": "几只猫", "score": 2}, // 模糊但正确
{"text": "3只狗", "score": 1} // 错误]},
// ... 共100条,每个样本至少2个回答,覆盖不同质量等级]关键要求:打分标准一致(如 “准确> 模糊 > 错误”),避免主观偏差(可多人标注取平均)。
LLM 和 Diffusion 模型的关系(呼应你之前的问题)
✅ 现代多模态大模型(如 GPT-4V、Gemini) = LLM(理解语言) + Vision Encoder(理解图) + Diffusion/Decoder(生成图)
核心应用场景:哪里需要 “循序渐进” 的模型?
这套范式几乎适用于所有需要 “理解人类需求、输出高质量结果” 的大模型场景,典型应用包括:
通用大模型(ChatGPT、Kimi、文心一言)
核心需求:能应对日常对话、知识问答、文本生成等多元任务,既要 “博学” 又要 “好用”。
三阶作用:预训练学海量知识,微调懂人类指令,RLHF 优化回答风格(如简洁、礼貌)。
垂直领域大模型(医疗、金融、法律)
核心需求:在专业场景中输出准确、合规的结果(如医疗诊断、法律文书)。
三阶作用:预训练学通用语言 + 基础专业知识,微调适配垂直领域指令(如 “解读病历”),RLHF 强化准确性(避免误诊、法律风险)。
多模态大模型(Seed1.5-VL、GPT-4V)
核心需求:理解图像 / 视频 + 文字,实现跨模态交互(如 “描述图片内容”“根据视频写总结”)。
三阶作用:预训练学图文对齐(图→文对应),微调懂跨模态指令,RLHF 优化多模态回答的连贯性。
智能代理(AutoGPT、AgentGPT)
核心需求:能自主完成复杂任务(如 “写报告→查资料→排版”),需要逻辑链和执行能力。
三阶作用:预训练学逻辑推理,微调学任务拆解指令,RLHF 优化执行效率(避免无效步骤)。
RLHF
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是当前大语言模型(LLM)对齐人类意图、提升有用性与安全性的核心技术。它让 AI 从“只会背书”变成“懂你想要什么”。
一、为什么需要 RLHF?——问题背景
❌ 预训练 + 微调(SFT)的局限
预训练模型:在海量文本上训练,目标是“预测下一个词”,但不知道什么是“好回答”。
监督微调(SFT):用人工写的“指令-回答”对微调,让模型学会格式。
但 SFT 数据有限,且无法覆盖所有场景;
模型可能生成看似合理但事实错误、有害或冗长的回答。
🎯 核心问题: 如何让模型不仅“语法正确”,还符合人类偏好(真实、简洁、有帮助、无害)?
二、RLHF 的核心思想
让人类当“裁判”,教 AI 什么是好答案;再用强化学习,让 AI 主动优化输出。
它不直接告诉模型“正确答案是什么”,而是告诉它:“这个答案比那个更好”。
三、RLHF 的三大步骤(详细流程)
步骤 1️⃣:收集人类偏好数据(构建奖励信号)
让人类标注员对同一个问题的多个模型回答进行排序。
例如:
问题:
如何煮鸡蛋?回答 A:
把鸡蛋放水里煮10分钟。回答 B:
先买一只鸡,等它下蛋...(跑题)标注员选择:A > B
收集大量这样的 (prompt, chosen_response, rejected_response) 三元组。
💡 关键:比较式反馈比打分更可靠(人很难给“7.3分”,但容易判断“A比B好”)。
步骤 2️⃣:训练奖励模型(Reward Model, RM)
用上一步的数据,训练一个独立的神经网络(通常也是 Transformer),叫做 奖励模型(RM)。
输入:
(prompt, response)输出:一个标量分数(reward),表示这个回答的“好坏程度”。
训练方式:
对每一对
(chosen, rejected),让 RM 满足:
reward(chosen) > reward(rejected)常用损失函数:Pairwise Ranking Loss(如 Bradley-Terry 模型)
✅ RM 的作用:代替人类,24小时自动给任意回答打分。
步骤 3️⃣:用强化学习优化语言模型(Proximal Policy Optimization,ppo)
现在,我们有一个:
待优化的策略模型(Policy):即原始 LLM(比如 SFT 后的模型)
奖励模型(RM):能给回答打分
目标:调整策略模型的参数,让它生成的回答获得更高的 RM 分数。
具体做法(以 PPO 算法为例):
让策略模型对一批 prompts 生成 responses;
用 RM 给这些 responses 打分 → 得到 reward;
使用 PPO(Proximal Policy Optimization) 算法更新策略模型:
鼓励生成高 reward 的回答;
同时限制更新幅度,避免模型“学歪”(KL 散度约束)。
🔁 这是一个闭环迭代过程:生成 → 打分 → 更新 → 再生成……
四、RLHF 的整体架构图(文字版)
[人类标注员]
↓
(问题 + 多个回答) → [排序/选择] → (偏好数据)
↓
[奖励模型 RM 训练] ← (偏好数据)
↓
[策略模型 π] → 生成回答 → [RM 打分] → [PPO 强化学习] → 更新 π
↑_________________________________________|五、RLHF 的效果 vs 没有 RLHF
📊 OpenAI 实验表明:1.3B 参数的 InstructGPT(带 RLHF) > 175B 的 GPT-3(无 RLHF) 在人类偏好上!
六、RLHF 的挑战与局限
⚠️ 1. 人类偏好不一致
不同标注员标准不同(文化、背景、情绪);
“好答案”本身主观(幽默 vs 严肃)。
⚠️ 2. 奖励模型可能出错
RM 只见过有限样本,面对新问题可能打分不准;
可能被策略模型“欺骗”(Reward Hacking)。
⚠️ 3. 成本高昂
需要大量高质量人工标注;
强化学习训练不稳定、计算量大。
⚠️ 4. 过度优化导致“讨好”
模型可能回避争议话题,变得过于保守;
丢失创造性或多样性。
七、RLHF 的演进与替代方案
由于 RLHF 成本高、复杂,社区也在探索更高效的方法:
💡 趋势:RLHF 是里程碑,但未来可能被更简单的偏好优化方法取代。
八、一句话总结 RLHF
RLHF = 人类当裁判 + 训练一个 AI 裁判(RM)+ 用强化学习让 LLM 主动讨好这个裁判,最终生成更符合人类喜好的回答。
它不是让 AI “变聪明”,而是让它 “更懂你”。
如果你正在做 LLM 应用,理解 RLHF 能帮你明白:
为什么 ChatGPT 比原始 GPT 更“听话”;
为什么不能只靠 prompt engineering 解决所有问题;
如何设计自己的对齐(Alignment)流程。
大模型解码策略
大模型的解码策略 - 白玉京的文章 - 知乎
https://zhuanlan.zhihu.com/p/1986752240992658717
解码策略 (Decoding Strategy),即大模型的“选词规则”。
虽然“预测下一个词”的原理很简单,但在每一步如何从成千上万个候选词元的概率分布中做出最终选择,却是一门艺术。
一、确定性策略:稳字当头,注意力帮它“不短视”
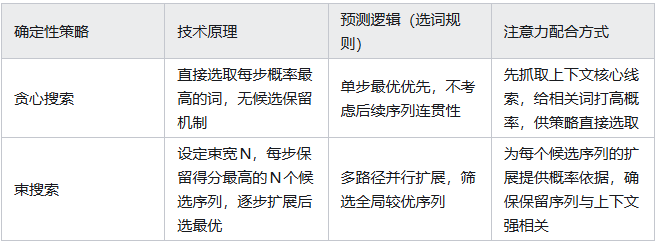
1.贪心搜索:每步只选“最像对的词”
策略原理:最简单粗暴的规则——每一步都直接选注意力机制给出的“概率最高的词”,不考虑其他候选。
注意力的配合逻辑:注意力机制先从上下文里抓核心线索,给相关词打高概率,贪心搜索直接“抄作业”选最高的。
文本例子:输入“小明在图书馆,他______”
第一步,注意力机制先“聚焦”:
关注“小明”(“他”的指代对象)、“图书馆”(场景),给相关候选词打分:“看书”(概率0.6)、“学习”(概率0.25)、“跑步”(概率0.03)、“吃饭”(概率0.02);对“在”“的”这类虚词,注意力权重几乎为0。
第二步,贪心搜索选词:直接选概率最高的“看书”,生成“小明在图书馆,他看书”;
下一步继续重复:注意力关注“看书”“图书馆”,给“认真地”(概率0.5)打分最高,贪心搜索选它,最终生成“小明在图书馆,他看书认真地做笔记”。
优点:速度最快,几乎不耗额外算力;
缺点:短视效应明显——可能每一步选的都是局部最优,但整体序列生硬。比如输入“我喜欢春天,因为______”,贪心可能生成“我喜欢春天,因为春天春天春天很温暖”(每一步“春天”概率都高,导致复读)。
2.束搜索:多开几条路,最后选最优
策略原理:贪心搜索的升级版,核心是“不把鸡蛋放一个篮子”。设定一个“束宽”(比如4),每一步都保留注意力机制给出的“得分最高的4个候选序列”,后续基于这4个序列继续扩展,直到生成结束,再从所有候选里选最优的。
文本例子:输入“晚霞染红了天空,______”,束宽=2
第一步,注意力聚焦“晚霞”“天空”,给出候选词及概率:“云朵”(0.4)、“余晖”(0.3)、“雨水”(0.05)、“马路”(0.04);
束搜索保留前2个序列:①“晚霞染红了天空,云朵”(累计得分0.4)、②“晚霞染红了天空,余晖”(累计得分0.3);
第二步,基于两个序列分别扩展:
对序列①,注意力关注“云朵”“晚霞”,给出候选词:“像棉花糖”(0.35)、“飘向远方”(0.25);累计得分0.4+0.35=0.75;
对序列②,注意力关注“余晖”“晚霞”,给出候选词:“洒在屋顶”(0.3)、“渐渐消散”(0.2);累计得分0.3+0.3=0.6;
束搜索继续保留前2个序列:①“晚霞染红了天空,云朵像棉花糖”(0.75)、②“晚霞染红了天空,余晖洒在屋顶”(0.6);
生成结束后,选得分最高的①作为最终输出。
优点:比贪心搜索更连贯,逻辑更严谨,不会出现明显的复读或跑偏;
缺点:计算量随束宽增大而增加(但远低于穷举);生成内容偏保守,缺乏新意——比如输入“写一句关于旅行的感悟”,永远都是“身体和灵魂,总要有一个在路上”这类套话。
二、随机性策略:灵活多变,注意力帮它“不胡说”
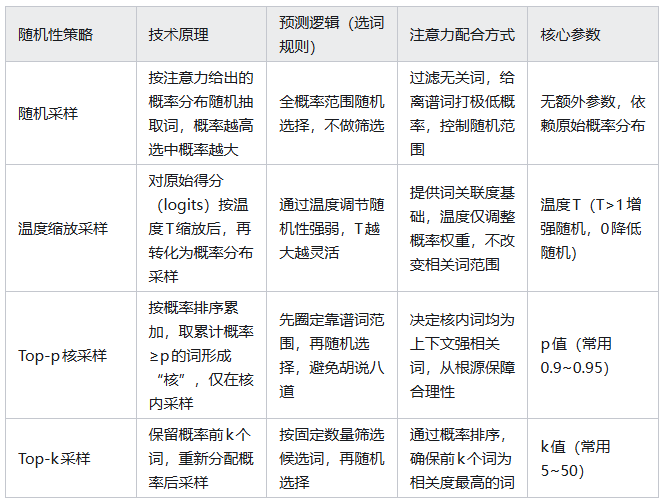
这类策略的核心是“主动引入随机性”,相同输入可能得到不同输出,适合对话、创意写作等需要多样性的场景。注意力机制在这里的作用是“拉缰绳”,避免随机选到无意义的词。各策略的技术原理与预测逻辑如下表:
MoE 的崛起:架构演进,从“稠密”到“稀疏”
多模态大模型主流架构介绍:从 LLaVA 到 Qwen3-VL,解构多模态大模型的演进之路 - 我要吃鸡腿的文章 - 知乎
https://zhuanlan.zhihu.com/p/1963658684765833212
传统的 LLM 通常是“稠密”的,即在推理时需要激活模型的所有参数。而以 Qwen3-VL 为代表的新一代 MLLM,其语言模型部分已经开始采用更先进的混合专家 (Mixture of Experts, MoE) 架构。
在 MoE 架构中,模型内部包含多个“专家”子网络。对于每一个输入的词元,一个“门控网络”会智能地选择激活一小部分最相关的专家来进行计算,而其他专家则保持“沉默”。这种“稀疏激活”的策略,使得模型可以在大幅增加总参数量的同时,保持推理计算量不变,从而在性能和效率之间取得了更好的平衡。