ViT + Connector + LLM:
多模态大模型主流架构介绍:从 LLaVA 到 Qwen3-VL,解构多模态大模型的演进之路 - 我要吃鸡腿的文章 - 知乎
https://zhuanlan.zhihu.com/p/1963658684765833212
MLLM 的“眼睛” (ViT)(只有encoder)、“大脑” (LLM) 和连接它们的“灵魂之桥” (Connector)。
Image
↓
Vision Encoder(ViT / CNN)视觉编码器
↓
Projection / Adapter
↓
LLM(GPT / LLaMA)
↓
Text
1️⃣ 图片 → ViT → 一堆视觉 token
2️⃣ 通过 连接器connector 映射到 LLM token 空间:
将 ViT 输出的视觉特征,精准地投影 (Project) 或翻译 (Translate) 到 LLM 能够理解的同一个向量空间中,实现视觉与语言的无缝对齐。
3️⃣ 当成“特殊文字”喂给语言模型
4️⃣ LLM 开始推理 + 说话
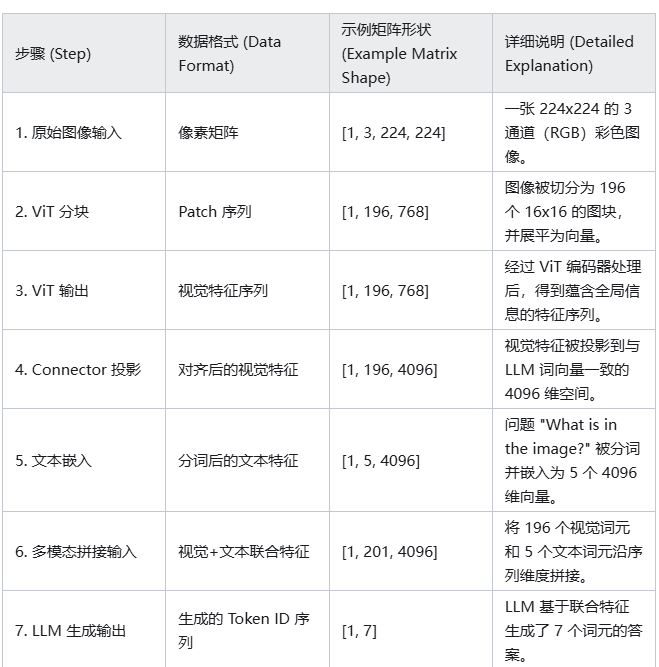
如表格第 6 步所示,最终送入 LLM 的,是一个全新的、更长的序列。在这个例子中,序列的总长度变成了 196 + 5 = 201。这个序列的前 196 个位置,承载着图像的全部视觉信息;而紧随其后的 5 个位置,则明确了用户的意图和问题。LLM 的自注意力机制将在这个统一的序列上运作,使得文本词元可以“关注”到视觉词元,反之亦然,从而实现了真正意义上的图文理解。
例如,当用户输入一张图片并提问“What is in the image?”时,LLM 的最终输入会是 [视觉词元1, ..., 视觉词元196, "What", "is", "in", "the", "image", "?"] 这样拼接后的形态。
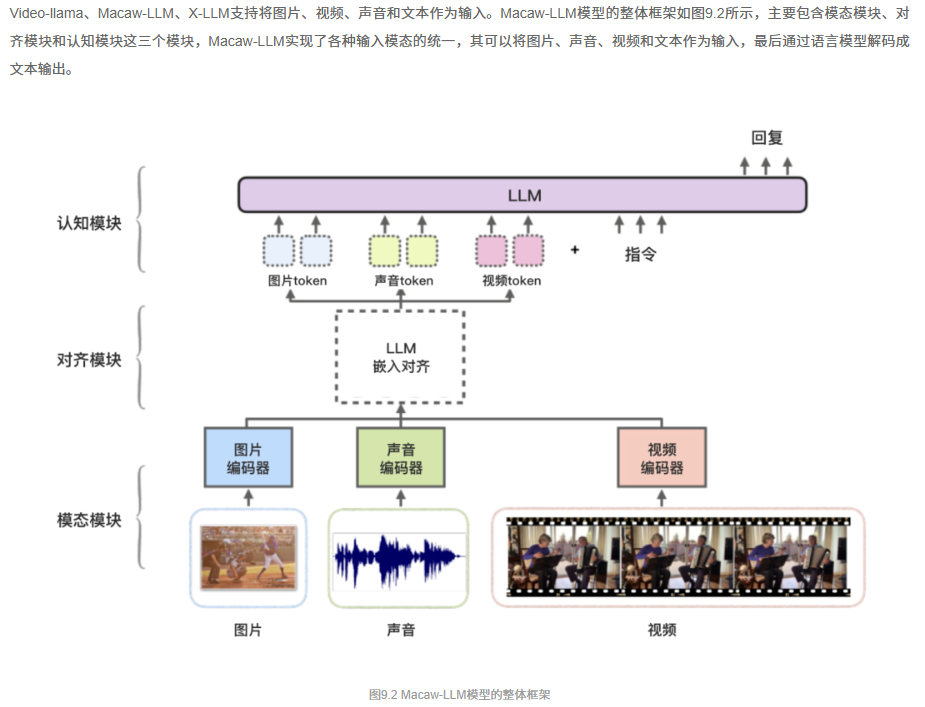
Connector的两种流派:
1.线性投影层 (Linear Projection)
这种连接器在结构上通常是一个非常简单的多层感知机 (MLP),甚至可以只是一个单层的全连接网络。它的核心任务就是进行一次线性的维度变换,将输入的视觉特征向量(如 768 维)映射到 LLM 的隐藏空间维度(如 4096 维)
2.Q-Former
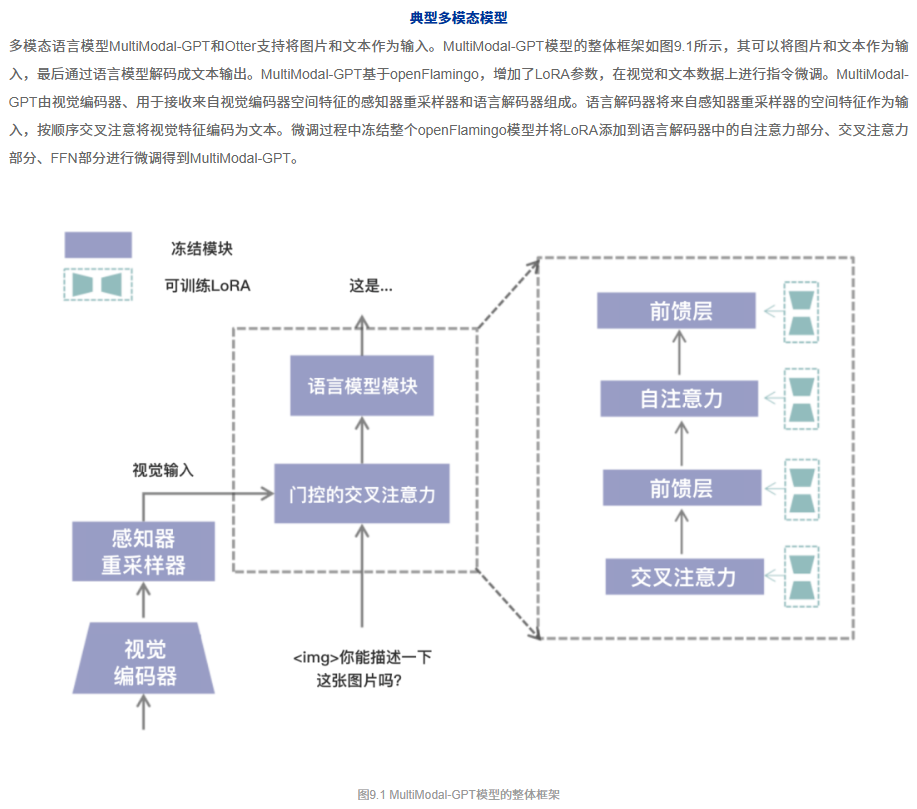
与 LLaVA 的极简主义形成鲜明对比的是以 BLIP-2 模型为代表的精巧设计——Q-Former。它认为,“翻译官”不应该只是一个被动的“传声筒”,而应该是一个能够主动思考、提炼关键信息的“专家”。
多模态VQA:
VQA
输入:🖼 图像 + 📝 问题
输出:📝 答案
多模态 QA 的几种常见类型(论文里常见)
1️⃣ 感知型(Perception)
Q:图中有几只猫?
考:
目标检测
数量理解
2️⃣ 属性型(Attribute)
Q:左边的车是什么颜色?
考:
空间定位
属性绑定
3️⃣ 关系型(Relation)
Q:哪个人站在桌子后面?
考:
关系理解
空间推理
4️⃣ 推理型(Reasoning)⭐
Q:这个场景中,哪件物品最可能被用来开瓶?
考:
视觉理解
常识推理
一个「判断你是否真的理解了」的小测试
你现在能不能分清这两句?
1️⃣ “请描述这张图片。”
2️⃣ “为什么图片中的人要这样做?”
如果你知道:
1️⃣ 不是 QA
2️⃣ 是 多模态 QA(推理型)
那你已经真的懂了。
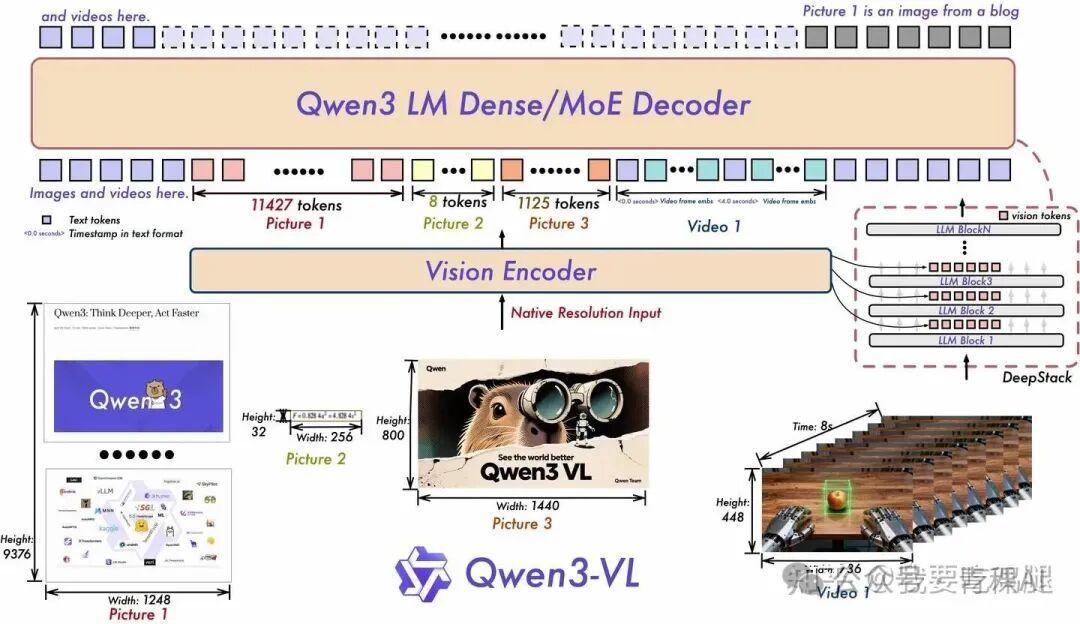
QWen3-VL
链接:https://zhuanlan.zhihu.com/p/1993069200495894656
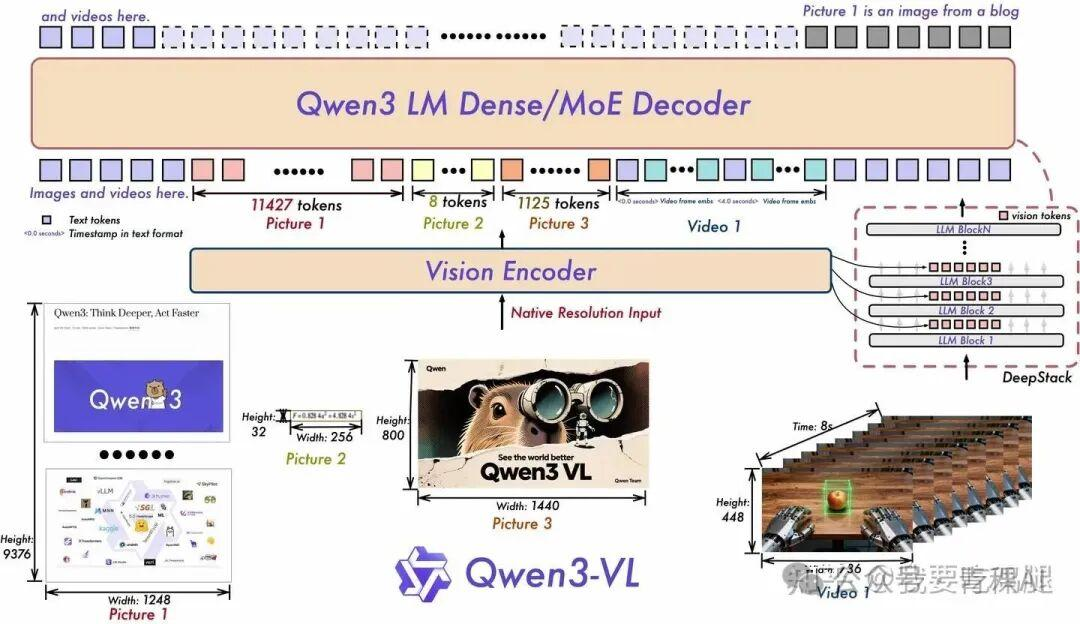
一. DeepStack 模块的引入
DeepStack 技术。这是一种全新的融合范式,我们可以将其理解为:从视觉编码器到语言模型的一次“单向握手”,升级为了一场贯穿始终的“多层次深度对话”。
上图右侧清晰地展示了 DeepStack 的工作原理。传统的 MLLM 仅将 Vision Encoder 最后一层的输出特征送入 LLM 的输入层。而 Qwen3-VL 则不同,它的 Vision Encoder 会像一个“信息分发站”,从其多个不同深度的中间层(例如第 8、16、24 层)提取出不同抽象层次的视觉特征。然后,这些特征会被精准地注入 (inject) 到 LLM 解码器相对应的前几个层(如 LLM Block 1, Block 3, ...)中。
二.MRoPE-Interleave
一种更先进的多维旋转位置编码,通过交错 t, h, w 三个维度的频率,让模型对视频的时空信息有更鲁棒的感知。
三.文本时间戳对齐机制
在输入端就将视频帧与精确的时间戳文本(如 <0.8 seconds>)进行绑定,让 LLM 具备了前所未有的、对视频事件进行精准时间定位的能力。

